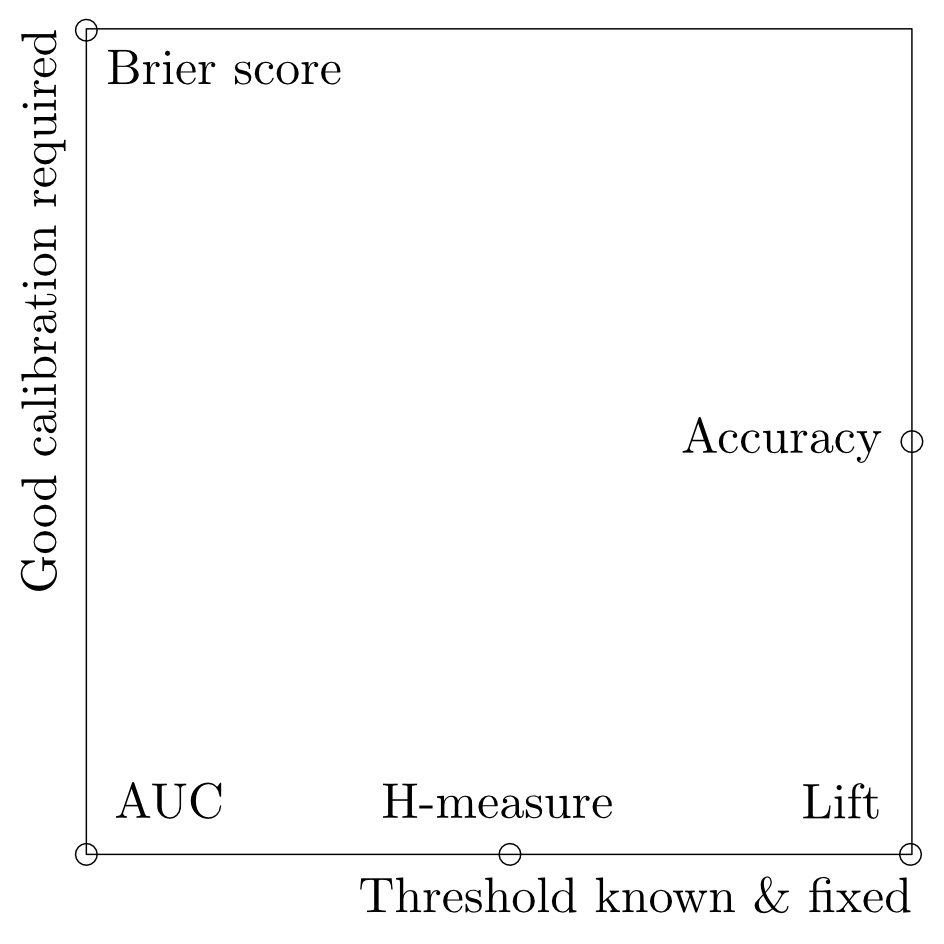
Each metric is suitable for a different task. And there are two questions we have ask to select an appropriate metric:
- Is the decision threshold known ahead and fixed?
- Do we need calibrated predictions?
Of course, sometimes we may want sometimes in the middle, because we have some knowledge about the distribution of the values in the cost matrix. Example measures that consider just a range of thresholds or weight the thresholds unequally are partial Gini index, lift or H-measure. If you have some information about the working region of the model, you should use a measure that takes that knowledge into account (see the correlations of measures in the second referenced article).
Another question to ask is whether we need calibrated results. If all we need is to rank results and pick top n% of samples, ranking measures like ROC-AUC or lift are appropriate, following the Vapnik's philosophy: "Do not solve harder problem than you have to". On the other end, if we need to asses risk, calibrated results are desirable. Measures that evaluate quality of calibration are Brier score or logarithmic-loss.
And of course, there are measures that are somewhere in the middle, like threshold-base measures, that evaluate quality of calibration at a single threshold, while ignoring the quality of calibration at the rest of thresholds.
A metric may also feature following desirable properties:
- Provides information about how much better is the model in comparison to a baseline for easier interpretation of the quality of the model.
- Works not only with binary, but also with polynomial labels.
- Is bounded for easier comparison of models across different datasets.
- Works also with unbalanced classes.
- Getting the Most Out of Ensemble Selection
- Benchmarking state-of-the-art classification algorithms for credit scoring: An update of research